韩国伦理电影 浅说念Elasticsearch的初学与奉行

Elasticsearch(ES)是一种基于分散式存储的搜索和分析引擎,现时在许多场景得到了浅显使用,比如维基百科和github的检索,使用的即是ES。ES中不乏纷纭冗余的细节,而本文将温暖其中枢性情:分散式存储性情和分析检索才略。围绕这两大中枢性情韩国伦理电影,本文将先容其中的宗旨、旨趣与奉行案例,但愿让读者快速剖析ES的中枢性情与应用场景。
中枢宗旨
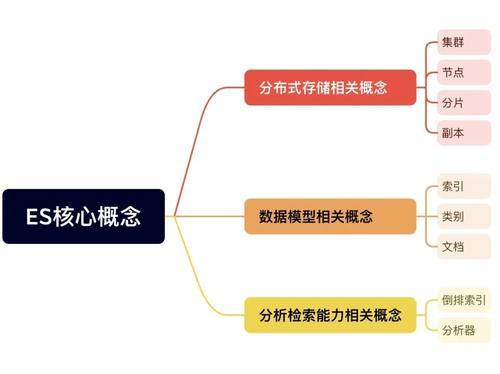
分散式存储性情辩论宗旨:
节点(Node)
节点即是单个的Elasticsearch实例,该实例运行的载体不错是物理做事器或假造机器。
集群(Cluster)
集群是节点的采集。
集群是一组运行在不同载体(物理或假造机器)上的一个或多个Elasticsearch节点的采集。在集群内,节点间互迎合营,对数据进行存储和处置。
分片(Shards)
分片是索引的片断。
受制于单个ES节点的性能上限(内存、磁盘IO速率),如若数据以整块体式进行存储与处置,则无法满盈快速地响应客户端的申请,因此ES将索引拆分为更小块的分片,以便分散式存储和并行处理数据。
副本(Replicas)
副本是分片的拷贝。
每个分片不错有零个或者多个副本,副本与分片对外都不错提供数据查询做事。副本的存在不错加多通盘ES系统的高可用性,高并发性,因为分片能作念到的事情,副本也能作念到。操办机宇宙里莫得银弹,副本的支出主要体现时数据同步老本的加多(每次数据更新时,都需要把分片上的数据变更同步到其他副本中)。
激情文学小说网数据模子辩论宗旨
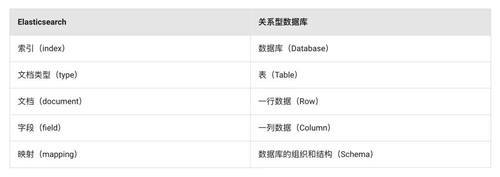
索引(Index)
索引由一个或多个分片构成。索引是Elasticsearch中的顶层数据容器,对应关系型数据库中的数据库模子。
类别(Type)
类别在较早的Elasticsearch版块中,一个索引不错包含多个类别,每个类别用于存储不同种类的文档。对应关系型数据库中的数据表。关联词,在Elasticsearch 7.0以后,类别慢慢被弃用。原因是兼并索引下,不同type的数据存储其他type的field,包含大都空值,形成资源浪费。
文档(Document)
索引中的每一条数据叫作一个文档,它是一个JSON样式的数据对象。对应关系型数据库中的数据行。这小数与非关系型数据库MongoDB很访佛,MongoDB属于文档数据库,每条数据亦然一个BSON文档(BinaryJSON)。非关系型数据库的文档比较关系型数据库的数据行,上风在于提供了更高的目田度,文档中不错简短地新增减字段,多个文档间也不要求字段十足一致。同期,文档也保留了一部分结构化存储的性情,对存储的数据进行了一定的结构化封装,而莫得像K-V非关系型数据库那样十足撤消数据的结构化。
分析检索才略辩论宗旨
倒排索引(Inverted Index)
倒排索引是Elasticsearch顶用于高效检索文档的症结数据结构。它是将文档中的每个单词映射到包含它的文档上。这种数据结构使得Elasticsearch约略高效地处理文本信息这类非结构化数据,比较传统关系型数据库的正排索引遍历通盘数据表,它约略高效地进行文本检索与分析。
正排索引是从文档到症结字的映射(已知文档求症结字),倒排索引是从症结字到文档的映射(已知症结字求文档)。倒排索引由两个主要部分构成:词汇表(Vocabulary)和倒陈列表(Inverted List)。词汇表存储了系数不同的单词,而倒陈列表存储了每个单词文档中的分散情况。
分析器(Analyzer)
分析器是Elasticsearch用于进行文本预处理的组件。它的主要作用是将文本回荡为可被倒排索引的单词(term)。分析时时由以下几个法子构成:
分词(Tokenization):将文本拆分红单词,关于英文,以空格为分界线来拆分单词。
标准化(Normalization):对单词进行标准化,时时包括大小转小写、去除停用词等。
过滤(Filtering):过滤掉极度字符,举例移除特定字符、删除数字替换等。
在阿里云DTS数据同步用具中,不错选拔一系列ES内置的分析器,然而Elasticsearch的内置分析器关于中语的支合手较差,采选了暴力拆分每个中语单字的战略。如若但愿对中语进行合适的分词,不错选拔第三方分词器,比如jieba分词器。
主要查询类型
基于以上的中枢宗旨,Elasticsearch通过分散式存储结构和分析检索才略,支合手并提供了多种不同类型的查询才略,用于称心各式检索需求。以下是ES中主要的查询类型:
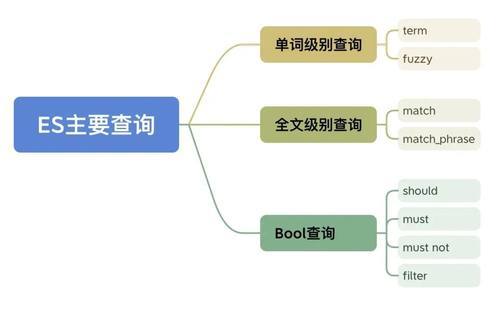
单词级别查询
万丈高楼深谷起,优秀的全文索引才略是由基础的单词查询才略撑合手的。
Term Query(精准)
最基础的ES查询,把输入字符串全部看作一个齐备的单词,然后去倒排索引表内部找。
Fuzzy Query(恶浊)
带裁剪距离的term查询。具体落幕:给定一个恶浊度(裁剪距离),ES会证实这个裁剪距离,对原始的单词进行拓展,生成一系列候选的新单词。对每一个裁剪距离内的新单词,作念term查询。
全文级别查询
像使用match和match_phrase这么的高层查询都属于全文级别查询,全文级别查询是对多个/多种单词级别查询的封装。
match
match是自顺应的:
如若给定了恶浊度参数fuzziness,match在单词级别查询上会调用fuzzy querry;如若未给定此参数,则match在单词级别上会走term query;
如若analyzed,match会对输入进行分词,把输入"service_123456"算作"service"和"123456";如若not_analyzed,match走十足匹配,把输入"service_123456"算作"service_123456"。
match 查询的主要法子:
i.查验字段类型,稽察字段是analyzed照旧not_analyzed;
1.如若analyzed,讲解该字段仍是被分析器处理过,match会对输入进行分词;2.如若not_analyzed,讲解该字段未被分析器处理过,match走十足匹配;
ii.分析查询字符串,将输入字符串进行分词,对分出来的每个单词,证实是否设立了恶浊度参数fuzziness,选拔走term query或者fuzzy query;
iii.文档评分操办。
match_phrase
在match查询的基础上,保证输入的单词之间的轨则不变才会掷中,性能比较match会差一些。
Bool查询
用于落幕复杂的组合查询逻辑,具体有四种:
should:或
must:且
must _not:非
filter:不错用于作为查询中的前置过滤要求,must访佛,鬼父3克己是它不会参与操办辩论性分数。
逻辑完备性:满盈数目的或且非,不错落幕任何逻辑。
Term Query的文档辩论度得分操办方式
愚弄倒排索引,关于输入的单词,辩论每个文档的以下筹画:
TFIDF
宗旨:用文档中的一个单词,在一堆文档中分手出该文档;
TFIDF = TF * IDF;
TF(term frequency):词频。示意单词在该文本中出现的频率(单词在该文本中出现的多未几);
IDF(inverse document frequency):反向文档频率。 示意单词在通盘文本蚁勾搭出现的频率(有若干文本包含了这个词)的倒数,IDF越大示意该词的迫切性越高,反应了单词是否具有distinguish其场所文本的才略。
字段的长度
字段越短辩论度越高;
抽象这两个筹画得出每个文档的辩论度评分_score。
Elasticsearch奉行
Elasticsearch落幕nextToken分页
在做事端开导的奉行中,由于数据量大,不成能一次申请一次查询就复返全部数据。因此,对数据进行分页查询是一种常见的工程奉行。而由于ES简瑕疵理非结构化字段的才略,时时被用作搜索框API中的主力分页查询。
在ES中,内置的分页机制为sort+Search After分页。它会对每次申请生成一个游标字段,这就卓绝于符号了上一页的落幕位置,因此下次申请唯有从上一次的游标字段运转,就约略简短地查找下一页。这履行上是ES官方提供的一种nextToken分页落幕,它不详掉了构建游标这一历程,只需要使用者在查询要求中给定排序字段。
咱们也不错手动构建查询要求,手动落幕nextToken分页要求。即使你不纯属nextToken分页和ES查询的具体用法,你也应该能作念出以下判断:你一定不错用ES的查询要求落幕狂放的nextToken分页逻辑。事理是ES的Bool查询具有逻辑完备性。
这么作念的克己是,如若姿首中触及到多种数据库的分页,则后端代码的分页逻辑不错共用,只需要在不同的数据库中落幕调换的nextToken要求:
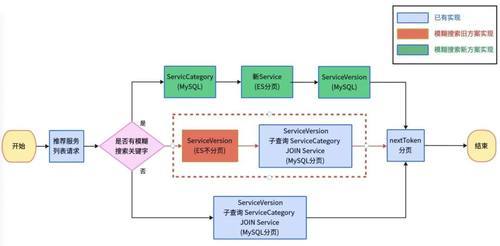
在上述姿首中,一个API做事使用到了两条查询链路:一条纯MySQL的查询链路,另一条ES分页+MySQL补字段的查询链路。由于在ES分页中,咱们仍是手动复现了MySQL中的nextToken分页要求。因此,在查询落幕后,封装nextToken分页申请的这部分后端逻辑就不错落幕复用。如若MySQL基于自落幕的nextToken分页而ES使用官方推选的Sort分页,则复用性较差,需要两套分页逻辑。
Elasticsearch关联查询与数据同步
关联查询有筹画:
ES与非关系型的文档数据库访佛,基于文档存储数据,莫得固定的表结构。关系型数据库以二维表结构的体式来组织数据,并擅长提供对数据表间关系的处置。而ES以文档为数据的组织体式,进行扁平化存储,它不擅前途行关系处置而擅长对扁平化的文档进行文本检索。
在ES中,由于其分散式存储性情和非关系性数据模子,访佛关系型数据库中JOIN联表查询这么的操作将相当未便。ES内置了访佛MySQL的JOIN的关联查询落幕:父子文档,但它存在功能和性能上的为止:父子文档需要在在兼并个分片中,罕见落幕关系处置需要的老本。ES官方时时不提出使用这种方式。
在ES中,如若要落幕关联查询,奉行一般为构建宽表或采选做事端JOIN这种折中有筹画。
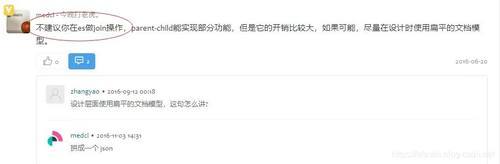
做事端JOIN
ES均分两个索引来存储数据,查询时在做事端的业务代码内进行两次查询,将第一次查询的后果作为第二次查询的要求。
克己:落幕容易,数据量少时用户体验好。
坏处:数据量大时,两次查询会带来罕见的支出,因为每次查询都需要建设相接、发送申请......
拓展:如若触及不同数据库之间的关联查询,也不错秉承此有筹画,比如用ES处理有限的文本字段,查得一个id列表,然后把这个id列表给MySQL的齐备查询作为要求,补都剩下的字段。
宽表冗孑遗储:
宽表:世俗地讲即是字段好多的数据库表。指的是把特定的查询业务需求所需要的全部字段都关联在沿路的一张数据库表。由于关联了大都冗余字段,宽表仍是不合适数据库遐想的三范式,而因此取得的克己即是查询性能的提升与关联查询的简化(逃匿了查询时JOIN)。这是一种典型的空间换时辰的优化念念路。但宽表未便膨胀,如若业务需求有变化,哪怕是需要新增一个字段,都需要变更宽表。
窄表:严格按照数据库遐想三范式遐想的数据表。这种表的遐想体式减少了数据冗余,然而落幕一个复杂查询要使用好多张表,触及多表JOIN问题,可能会影响性能。其特色是简短膨胀,多个窄表不错组合并顺应多种业务场景,不管有若干不同的场景,都无谓修改正本的表结构。但在查询逻辑和代码逻辑上需要进行封装。
如若对查询速率性能要求较高,提出选拔宽表。
数据同步
由于ES擅长检索而不是存储,业务场景中很少会以ES作为主力作念数据存储,而是使用关系型数据库进行存储,在需要ES时再构建需要的数据并进行同步。具体来说,有手动写入和数据同步用具等有筹画。
手动写入
在已有的业务逻辑中,同步或奇观象加多对ES的增点窜查。落幕概略,但不利于膨胀,耦合性较强。
数据同步用具
阿里云DTS:
是阿里云提供的一种云做事居品,基于binLog模拟主从复制落幕数据同步。一双一数据同步简短高效,但对多表JOIN场景无法支合手。如若表结构出现变更,则需要手动删除标的ES库,重建同步任务。
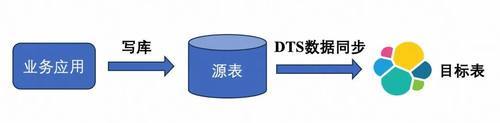
如若咱们搭建一个中间层,将多表JOIN后果先写入一个冗余的MySQL宽表,再同步到ES,则数据同步不错使用概略高效的DTS。代价是通盘同步链路关节增多,不富厚性加多了。
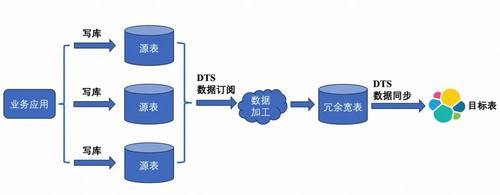
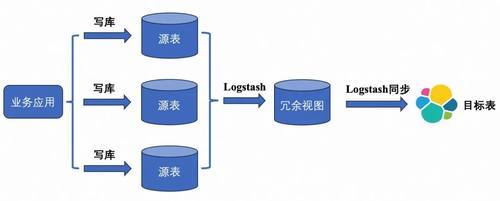
ES套件Logstash:
是ES官方套件系列中的数据同步用具。支合手在config树立文献中写入需要的SQL逻辑并存储为视图,并通过视图来写入多表查询的后果到ES。这种方式目田度较高,约略简短地构建所需要的数据。然而数据同步的性能略差(秒级别)。